Btrfs : révolution ou catastrophe ? Où en est-on aujourd'hui ?
Btrfs (prononcez « Butter FS ») est l'un des systèmes de fichiers les plus avancés disponibles aujourd'hui sous Linux. Il est moderne, repose sur des principes qui le rendent extrêmement fiable et propose de nombreuses fonctionnalités très intéressantes. Il est même utilisé par défaut par plusieurs distributions Linux.
Malgré cela, il se traîne une mauvaise réputation qui freine son adoption. Mais cette réputation est-elle vraiment justifiée ? C'est la question à laquelle on va essayer de répondre aujourd'hui !
Btrfs, un système de fichiers « nouvelle génération »
Btrfs est la contraction de B-TRee File System (ou « système de fichiers en arbre B » en français). Ce B-Tree est la structure de données qui sert de colonne vertébrale à Btrfs et lui garantit, en théorie, de bonnes performances lors de l'accès et de l'insertion de données (pour ceux à qui ça parle, un arbre-B a une complexité logarithmique).
À l'instar de nombreux autres systèmes de fichiers, comme Ext4, XFS, ou NTFS, Btrfs effectue son allocation par extent. Il s'agit pour le système de fichiers d'allouer un extent, c'est-à-dire une zone composée de plusieurs blocs de données contiguës, pour y stocker un fichier plutôt que d'allouer les blocs individuellement au fur et à mesure. Cela permet de limiter la fragmentation et de réduire la quantité de métadonnées nécessaires au stockage des fichiers, au prix d'une occupation d'espace disque un peu plus élevée.
Jusque là, rien de révolutionnaire. Ce qui le rend intéressant, ce sont les fonctionnalités dont il dispose, à commencer par le copy-on-write. Faisons donc un petit tour du propriétaire.
Copy-on-Write
La principale caractéristique de Btrfs est de faire du copy-on-write (ou copie sur écriture en français), plus souvent abrégée en CoW. C'est sur cette caractéristique que reposent une grande partie des fonctionnalités du système de fichiers, on va donc prendre le temps de la détailler un peu.
Sur un système de fichiers traditionnel, lorsqu'un fichier est modifié, la modification se fait directement sur place, en réécrivant par-dessus les anciennes données. Avec un système de fichiers pratiquant le CoW, les nouvelles données sont écrites ailleurs sur le disque, et une fois l'écriture terminée, les métadonnées qui indiquent où sont stockés les différents extents composant le fichier sont mises à jour.
Je vous invite à aller consulter les schémas de Sebsauvage pour mieux visualiser ce qui se passe.
La copie sur écriture offre plusieurs avantages à Btrfs. Du point de vue de l'intégrité des données tout d'abord : si une coupure brutale du système a lieu pendant la modification d'un fichier, on se retrouvera soit avec l'ancienne version du fichier, soit avec la nouvelle, mais on aura en aucun cas un fichier corrompu par une écriture non terminée.
Ensuite, cela ouvre la voie à de la déduplication : si plusieurs fichiers sont identiques ou contiennent des parties identiques, il est possible de stocker ces données identiques au même endroit sans craindre qu'elles ne soient modifiées. On économise ainsi de l'espace disque.
Enfin, en copiant simplement les métadonnées indiquant comment sont stockés les fichiers, on peut obtenir une « image » du disque dans un état donné, qu'il sera possible de restaurer par la suite.
Sous-volumes et instantanés
Btrfs est capable de gérer des sous-volumes. Il s'agit d'un découpage logique permettant de séparer différentes parties du système de fichiers au sein d'une même partition. On peut se les représenter comme des partitions en plus souples. Ce qui s'en rapproche le plus dans la stack linuxienne « traditionnelle », c'est LVM.
Par exemple, lorsque l'on installe un système GNU/Linux, on sépare souvent le système (/) et les données (/home) dans deux partitions différentes. Eh bah là on peut faire la même chose, sauf que les sous-volumes partagent l'espace de la même partition. On évite ainsi de perdre de l'espace en créant une partition système trop grosse, ou au contraire de se retrouver embêté après avoir rempli une partition système trop petite avec des containers Docker (oui, ça sent le vécu). 🙃️
Et les instantanés dans tout ça ? Les instantanés (ou snapshots en anglais) ne sont en fait que des sous-volumes, mais ayant un contenu initial (celui du sous-volume dont ils sont issus). Une snapshot ne consomme presque pas d'espace disque : il ne s'agit que d'une copie des métadonnées d'un sous-volume ; les données étant quant à elles identiques, elles ne sont pas dupliquées.
Mais que se passe-t-il lorsque l'on modifie un fichier dans le volume ayant servi à produire une snapshot ? Et bien grâce au mécanisme de copie sur écriture évoqué précédemment, le contenu de la snapshot n'est pas altéré, et seules les données modifiées consomment de l'espace disque supplémentaire.
Un point que je trouve intéressant avec la manière don Btrfs implémente les sous-volumes et les instantanés, c'est qu'ils sont exposés comme de simples dossiers. On les voit littéralement comme des dossiers dans son navigateur de fichiers.
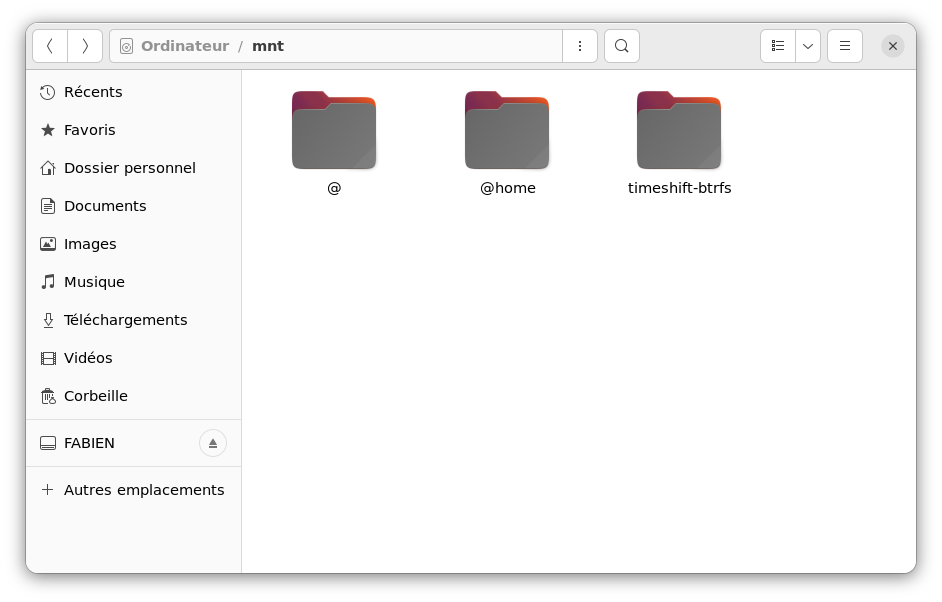
Ici, "@" et "@home" sont des sous-volumes : le premier contient le système et le second les données. "timeshift-btrfs" est quant à lui un dossier créé par le logiciel Timeshift pour y stocker les snapshots qu'il effectue.
Et cela permet de tout simplement utiliser les outils classiques dessus. Par exemple on peut supprimer une snapshot avec la commande rm ou la restaurer en la déplaçant avec mv :
# Suppression d'une snapshot
rm -rf /snapshots/2022-05-10/@home
# Restoration d'une snapshot
mv /@home /@home.bak
mv /snapshots/2022-05-16/@home /@home
Il faudra cependant passer par les outils spécifiques de Btrfs pour les créer.
Une dernière fonctionnalité intéressante avec les sous-volumes et les instantanés : il est possible de les envoyer sur un autre système de fichiers Btrfs. Et il est même possible de le faire de manière incrémentale lors de plusieurs envois successifs. Cela peut être utilisé pour répliquer / synchroniser rapidement des données entre deux machines ou pour implémenter un système de sauvegarde.
Multidisque (RAID)
Avec des systèmes de fichier classiques, comme Ext4 ou XFS, si on veut créer des partitions sur plusieurs disques, il faut soit utiliser une autre couche logicielle en dessous (dm-raid sous Linux) ou du matériel spécifique (une carte RAID) pour agréger les disques en un seul volume qui pourra alors être formaté avec le système de fichiers choisi.
Mais ceci n'est pas nécessaire avec Btrfs, car il supporte nativement un fonctionnement sur plusieurs disques et implémente ses propres configurations RAID. L'un des avantages à laisser directement Btrfs gérer son RAID, c'est qu'il est capable de s'autoréparer (self-healing) en cas de corruption de données.
Il faut en effet savoir que Btrfs conserve une somme de contrôle pour chaque bloc de données. À chaque fois que l'on va lire des données depuis le disque, Btrfs va utiliser ces sommes de contrôle pour s'assurer que ce qu'il est en train de lire n'est pas corrompu. Et lorsque c'est le cas, et que l'on est dans une configuration RAID apportant de la redondance (Btrfs RAID 1 par exemple), il sera capable d'aller récupérer la donnée sur un autre disque où elle est saine et automatiquement corriger la donnée corrompue. Et tout ça se fait de manière totalement transparente.
Compression
Il est possible d'activer de la compression sur les partitions Btrfs. Il y a plusieurs algorithmes parmi lesquels choisir en fonction de si l'on souhaite privilégier la rapidité ou l'efficacité de la compression. Cette compression est quoi qu'il en soit totalement transparente à l'usage : les données sont compressées / décompressées à la volée lors de la lecture ou de l'écriture.
Un point intéressant à noter : Btrfs est capable de détecter tout seul s'il est utile ou non de compresser un fichier donné. Par exemple si on écrit une vidéo sur le disque, la compresser n'aura aucun effet puisque celle-ci est déjà compressée avec des algorithmes bien plus adaptés. Btrfs ne perdra donc pas son temps à essayer de la recompresser.
Comment fait Btrfs pour déterminer ce qui doit être compressé et ce qui ne doit pas l'être ? Eh bien il commence par faire une évaluation statistique (basée sur l'entropie de Shannon) sur une portion du fichier, et s'il détermine que la compression ne sera pas efficace, il désactivera la compression pour ce fichier. Et si jamais la compression s'avère inefficace malgré l'évaluation statistique, il désactivera également la compression sur le fichier après coup.
D'où lui vient sa mauvaise réputation ?
Comme on l'a vu, Btrfs dispose d'une bonne quantité de fonctionnalités qui peuvent s'avérer précieuses au quotidien. Alors pourquoi n'est-il pas utilisé partout ? Où est le piège ?
Stabilité
Btrfs 1.0 a été intégré en 2009 dans Linux 2.6.29 alors qu'il n'était pas terminé. On se retrouvait d'ailleurs avec un message d'avertissement indiquant qu'il était « hautement expérimental » dès que l'on essayait de l'utiliser. Ce message a persisté pendant 4 ans. À cette époque, Btrfs était donc instable et beaucoup de ceux qui s'y sont frottés y ont perdu des données.
Il n'est donc pas rare de croiser sur les zinterwebs des témoignages sur le manque de fiabilité de Btrfs. Mais Btrfs est un système de fichiers activement développé, et ces problèmes de fiabilité font partie du passé. Il convient donc d'être critique avec ces témoignages. Il faut bien faire attention à la date à laquelle ils ont été postés et si leurs auteurs font référence à la fois où ils ont testé Btrfs il y a 10 ans ou s'ils l'ont utilisé plus récemment.
Il faut toutefois noter qu'aujourd'hui encore, certaines fonctionnalités de Btrfs ne sont pas totalement terminées et peuvent poser quelques soucis mineurs. Par exemple, à l'heure où j'écris ces lignes, la défragmentation ne conserve pas les liens de déduplication des données, provoquant une consommation d'espace disque supplémentaire (il existe heureusement des outils pour refaire cette déduplication).
Il y a également une fonctionnalité toujours instable dans Btrfs : les RAID 5 et 6, dont l'implémentation est problématique. Ils peuvent dans certaines circonstances très particulières entrainer une perte de données. Il ne faut donc pas les utiliser.
Si vous voulez connaitre l'état de chacune des fonctionnalités de Btrfs, tout est résumé dans le tableau suivant :
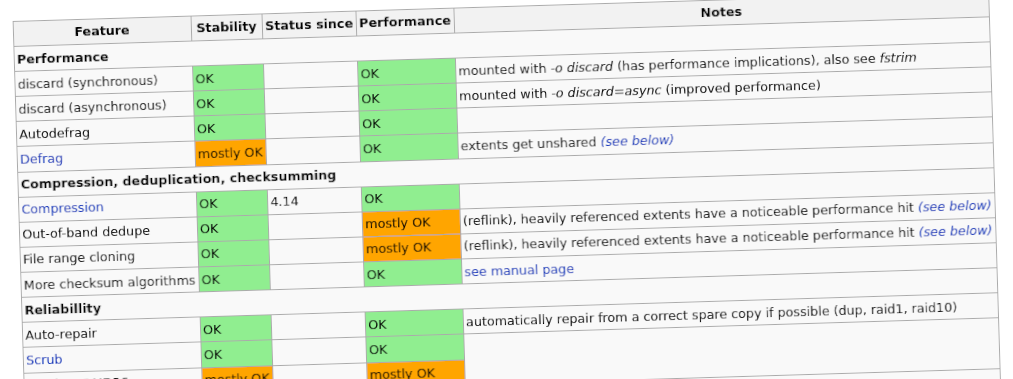
Note
En résumé : Btrfs était peu fiable par le passé et a très probablement été intégré trop tôt dans Linux. Mais en dehors des RAID 5 et 6, ce n'est aujourd'hui plus le cas.
Abandon par Red Hat
En 2017 Red Hat a annoncé qu'il ne supporterait plus Btrfs. Beaucoup y ont vu un signe annonciateur de la mort de Btrfs. Si Red Hat abandonne ce système de fichiers, c'est surement qu'il doit être inutilisable non ? La réalité est bien différente.
La décision de Red Hat provient de plusieurs facteurs. Premièrement, la demande pour Btrfs de la part de leurs clients était assez faible. Ceux qui utilisent RHEL (Red Hat Entreprise Linux) ont tendance à être plutôt conservateurs : ils préfèrent utiliser une technologie éprouvée plutôt que la dernière nouveauté.
Ensuite, et c'est le point le plus important, leur seul ingénieur qui avait une expertise sur Btrfs, puisque participant à son développement upstream, est parti chez Facebook. Et comme personne n'a repris le flambeau en interne, ne plus proposer Btrfs dans RHEL était probablement la meilleur chose à faire pour Red Hat.
Je vous invite à lire le poste de Josef Bacik (l'ingénieur en question), sur Reddit si vous souhaitez en savoir davantage.
Note
En résumé : Red Hat n'a pas abandonné Btrfs pour des raisons techniques, mais par manque de personnes compétentes en interne et par manque d'intérêt de la part de leurs clients.
Performances
Il est souvent reproché à Btrfs d'être moins performant que Ext4. Si on fait un benchmark de Btrfs vs Ext4, on peut constater qu'il est plus lent que Ext4 dans certaines situations, plus rapide dans d'autres, ça varie beaucoup d'un test à l'autre. Ces différences de performance s'expliquent en partie par l'utilisation du mécanisme de copie sur écriture, et par le fait qu'il vérifie l'intégrité des données lues (checksum).
Cependant pour une utilisation quotidienne, l'impact est négligeable et on ne le remarque même pas.
Il y a par contre quelques applications spécifiques où le copy-on-write pose de sérieux problèmes : lorsqu'un gros fichier subit des écritures intensives. C'est par exemple le cas des images disque des machines virtuelles, de Docker, ou encore les bases de données. Dans ces cas particuliers, la copie sur écriture dégrade énormément les performances et provoque une importante fragmentation.
Mais il ne s'agit pas d'un énorme problème en pratique : le CoW peut être désactivé pour un fichier ou un dossier spécifique.
Note
En résumé : Pour un usage de tous les jours, Btrfs ne pose pas de problème de performance particulier, et il s'améliore de version en version. Pour certains usages spécifiques, il faudra toutefois désactiver sélectivement des fonctionnalités comme le copy-on-write pour avoir de meilleures performances.
Et la concurrence dans tout ça ?
Dans un article comme celui-ci, il me parait important d'évoquer rapidement les autres systèmes de fichiers de nouvelle génération. Mais on aura vite fait le tour puisqu'ils sont très peu nombreux !
Le principal concurrent à Btrfs est ZFS. Il offre les mêmes fonctionnalités que Btrfs et plus encore, il est extrêmement stable et bien éprouvé. Son principal défaut est de ne pas être intégré au noyau Linux pour une bête histoire de licence.
L'autre système de fichiers qui pourrait concurrencer Btrfs à l'avenir se nomme Bcachefs. Il promet de belles choses sur le papier (fonctionnalités similaires avec de meilleures performances) mais il n'est pas encore terminé et n'a pas encore fait son chemin jusqu'au noyau Linux. Affaire à suivre donc. 🙂️
Mon avis sur Btrfs
Je pense que Btrfs est un excellent système de fichiers pour une utilisation sur une machine de travail. Il me semble parfaitement fiable pour un usage courant, et il est d'ailleurs utilisé par défaut sur openSUSE depuis 2014 et par Fedora depuis 2020. Il est également déployé à large échelle chez Facebook et dans les NAS Synology et Netgear, ce qui me semble être un gage de maturité technique.
J'apprécie tout particulièrement son système de sous-volume et de snapshot. Ils sont très simples à utiliser et permettent de se sortir d'un mauvais pas lorsque l'on bidouille son système ou lorsqu'une mise à jour tourne mal. Il existe d'ailleurs des outils graphiques comme Timeshift qui rendent cette fonctionnalité facilement accessible à tout le monde.
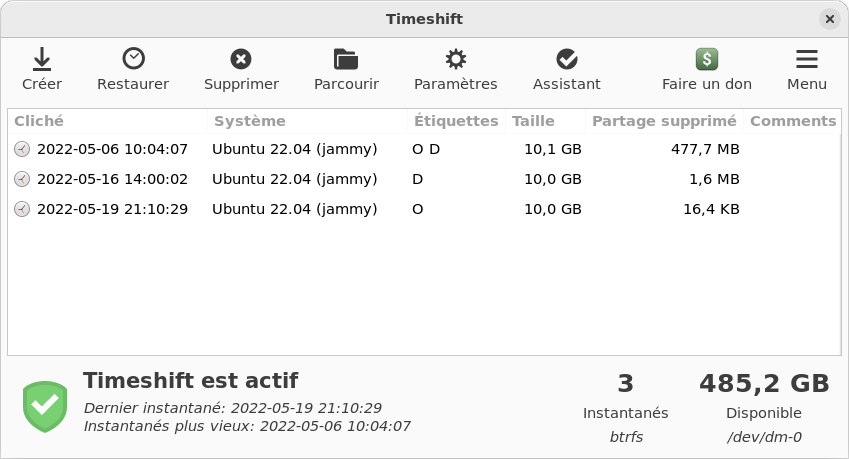
Je ne suis par contre pas très fan de la manière dont il implémente les RAID. Pour monter de gros stockages de données sur des serveurs je lui préfère ZFS que je trouve plus souple et dont le fonctionnement me convient mieux.
Vers l'infini et au-delà
Histoire de ne pas vous laisser sur votre faim, voici quelques documents que je trouve intéressants si vous souhaitez creuser davantage le sujet :
- « Battle testing ZFS, Btrfs and mdadm+dm-integrity » : un (très) long article dans lequel les configurations RAID de ZFS et Btrfs sont mises à l'épreuve afin de tester leurs limites et de voir à quel point elles peuvent résister à des problèmes divers (coupure de courant lors d'une écriture, corruption de donnée sur le disque, etc.). Cet article teste également une stack RAID plus classique sous Linux (dm-raid + dm-integrity).
- « I couldn't break Synology SHR+btrfs (yet) » : Synology utilise depuis quelques années Btrfs sur leurs NAS. Il l'utilise, mais à sa sauce. Cet article essaye donc de mettre à mal Btrfs sur un NAS Synology pour tester sa résistance.
- « Examining btrfs, Linux’s perpetually half-finished filesystem » : un article très critique sur Btrfs et notamment sur sa partie RAID.
- La page Btrfs du wiki de Sebsauvage dans laquelle il fait son retour d'expérience sur Btrfs. Vous y trouverez pas mal d'informations, d'astuces techniques et des pratiques qu'il a mis en place avec le temps.
- Et on ne pouvait pas faire autrement que de terminer sur la documentation officielle, qui devrait être en mesure de répondre à toutes les questions techniques que vous pourriez vous poser.
Voilà, c'est tout pour cette fois. J'espère avoir pu vous faire découvrir Btrfs ou vous apporter des éclaircissements à son sujet. N'hésitez pas à partager votre avis ou des articles que vous trouvez intéressants sur Btrfs dans les commentaires ci-dessous ! 😄️
L'image de couverture de cet article est dérivée d'une photo de Hannes Grobe, placée sous licence cc by-sa 4.0.
{kind=link}